docker部署dify+ollama
参考文档
dify社区文档:
csdn文档:https://blog.csdn.net/wade1010/article/details/141573513
https://blog.csdn.net/u010522887/article/details/141407784
deepseek技术社区:https://deepseek.csdn.net/67aaf7d42db35d11954178ea.html
github:https://github.com/songquanpeng/one-api/issues/1357
将dify码源克隆到本地环境
git clone https://github.com/langgenius/dify.git --branch 0.15.3
进入dify码源docker目录 复制环境配置文件
cd dify/docker
cp .env.example .env
检查docker版本和docker-compose版本
docker --version
docker-compose --version
Docker compose up -d 这里发现拉取失败是因为国内无法访问国外的docker镜像源
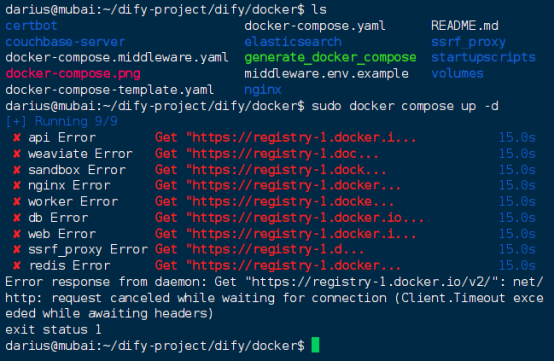
接下来更换国内的docker镜像源
sudo nano /etc/docker/daemon.json

重新加载docker镜像文件和重启docker服务
sudo systemctl daemon-reload
sudo restart docker
再次进行docker镜像拉取
sudo docker compose up -d
拉取成功
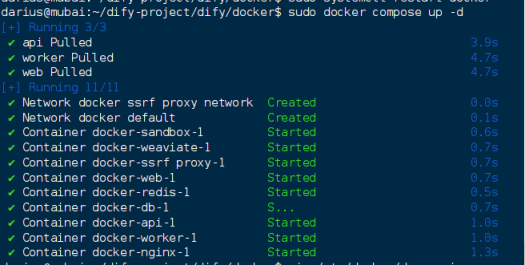
检查所有容器服务是否正常
docker compose ps

检查各个端口的状态

访问ip:80端口 成功进入到Dify页面
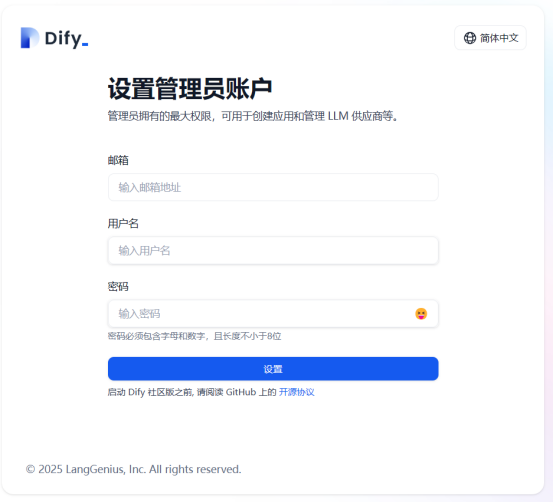
第二部分:开始部署ollama (linux部署)
curl -fsSL https://ollama.ai/install.sh | bash
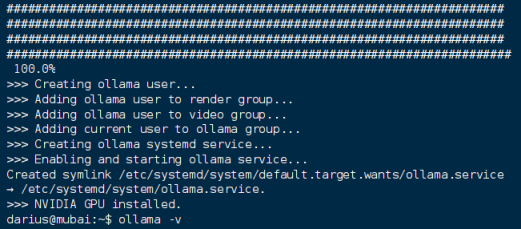
启动systemctl start ollama
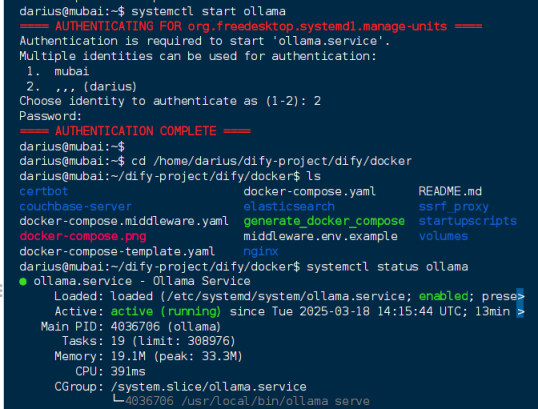
开始下载deepseek模型 这里下载的是14b版本
sudo ollama run deepseek-r1:14b

等待安装完成即可在linux上使用deepseek
3.将deepseek接入到dify平台
因为dify是在容器中部署 而deepseek是在ollama客户端中部署 dify容器中的网络无法直接访问到ollama端口,要将ollama服务暴露在网络中才能在dify添加url.
修改ollama服务的环境配置
sudo vim /etc/systemd/system/ollama.service
在Service中添加一行
Environment=”OLLAMA_HOST=0.0.0.0”
重启服务
sudo systemctl daemon-reload
sudo systemctl restart ollama
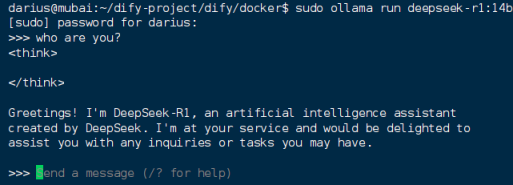
查看端口即可看到ollama服务已经暴露
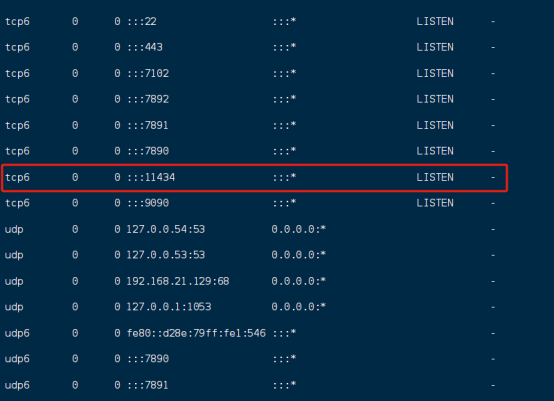
在dify上添加ollama模型
点击主页 创建空白应用 创建一个简单的文本对话模型 进行测试
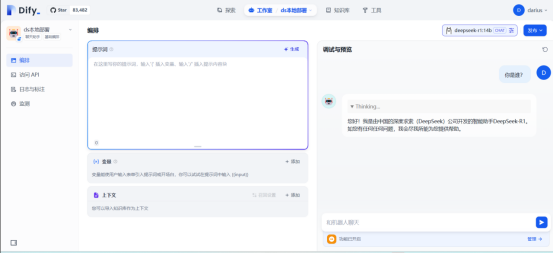
到此dify+ollama本地部署deepseek完成。
docker部署dify+vllm框架大模型私有化部署
参考文档:
VLLM社区:Quickstart - vLLMCSDN:https://blog.csdn.net/qq_46941656/article/details/119681765
https://zhuanlan.zhihu.com/p/687208224
https://east.moe/archives/1478
4.部署vllm
首先查看服务器支不支持cuda
可以用nvcc --version查看
如果不支持可以安装 sudo apt install nvidia-cuda-toolkit
使用conda来创建和管理python环境 需要主要python版本需要3.8-3.12
先去官网下载anaconda3
运行脚本 安装anaconda
bash Anaconda3-2024.10-1-Linux-x86_64.sh
安装的时候可能会默认安装在/root目录下,如果没权限要安装在/home/user目录下
回车+yes 下载即完成
修改.bashrc来激活安装
export PATH=~/anaconda3/bin:$PATH
Source ~/anaconda3/bin/activate
执行 source ~/.bashrc
完成后即可使用conda命令
可以用conda list 测试一下
Conda create --name myenv python=3.12 这里指定版本是3.12
Conda activate myenv
切换到刚刚创建的conda环境中执行安装vllm
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple vllm
这里安装时间很长且包含国外镜像,切换到国内镜像来进行安装会快很多。

通过nvida-smi 查看GPU信息,确保显存够用
国内环境直接从宝塔社区下载模型,国外从hugging face下载模型,but国内好像禁用了
宝塔:https://www.modelscope.cn/home
Hugging face :https://huggingface.co/
这里用的模型是Qwen2.5-14B-Instruct-GPTQ-Int4
开始部署大模型
vllm serve /home/darius/model/Qwen2.5-14B-Instruct-GPTQ-Int4
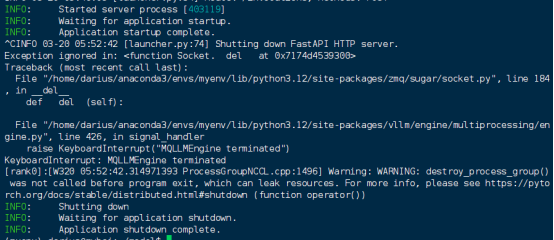
部署成功。
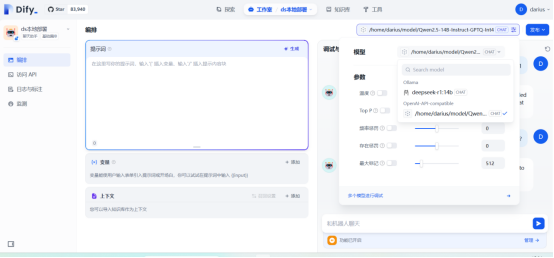
在dify里添加好名称和url
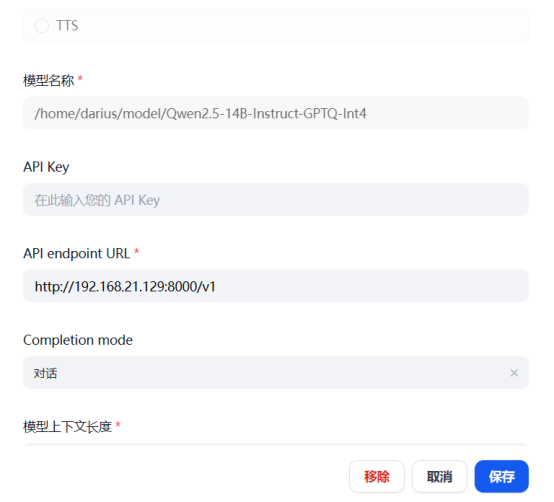
这里模型名称还得加上路径
Openai官方接口要带上目录
接入完成后创建应用测试
至此部署完成。